Minimizing Regret

Hazan Lab @ Princeton University
AI Alignment via Incentives and Correction
by Rohit Agarwal, Joshua Lin
It seems clear that the most important technology of today is artificial intelligence. Many methods to align agents often rely on simply instructing them to be aligned, e.g. Anthropic’s Constitutional AI. One well-known issue, though, is that even with these guardrails, models can produce false or generally misaligned responses.
Even in modern agentic pipelines for scalable oversight, in which large language models (LLMs) verify each other’s work, serious issues tend to arise. For example, consider the the context of problem-solving in math. Given a problem, a common setup involves a solver, who constantly proposes solutions, and a auditor, who tries to check the solutions for errors. Unfortunately, in practice it’s been found that auditors often “collude” with the solver—i.e., the auditor might let an incorrect solution through. This effect is especially prominent if the solver and auditor are calling each other in a loop or if the two agents share model weights.
How can we mitigate these issues? Today, we’ll discuss a new framework for aligning agents. Our proposal is that rather than telling agents to “be aligned”, or just asking them to review each other’s work, alignment requires setting up the proper incentives, rewards, and punishments to induce the desired behavior in AI models. Alignment therefore is a game-theoretic problem.
Alignment as Mechanism Design
It turns out that people have already extensively studied these kinds of incentives in humans. In his 1968 paper, Becker transformed the study of criminal behavior by introducing the “Rational Offender” hypothesis. He argued that the decision to commit a violation can be analyzed as an expected-utility calculation: a criminal is a rational actor who weighs the gain from misconduct against the probability of detection and the severity of punishment.
In a simple analogy, suppose we’d like to disincentivize drivers from speeding on highways. Intuitively, we might want to increase the amount of highway patrol, as well as the penalty for speeding. However, having more cops is costly—and if everyone has stopped speeding anyways from fear of being ticketed, it doesn’t make sense to keep funding such a large police force. But once people realize the oversight is gone, they’ll start speeding again! It turns out that by modeling this kind of phenomenon through a game-theoretic lens, we can show that maximizing societal utility (i.e., minimizing the amount of speeding while keeping policing costs low), we must continually adapt the rewards and punishments provided to all parties involved.
We can think of this being done on two timescales, formulated as a bilevel game. First, the fast timescale: for a fixed reward configuration, one player decides whether or not to speed, and the other decides whether or not to patrol. Rational agents will adapt their play to maximize their individual rewards, naturally reaching some type of equilibrium. However, by changing the reward configuration on a slow timescale, we can induce different changes in the agents’ behaviors, constantly shifting the equilibrium! By carefully adapting the rewards, we can always keep the state near the optimal state for society’s values, even when it’s not an equilibrium for the players under any fixed reward configuration.
Experimental Results on LLM Programming
This model can be applied to interactions between LLMs by replacing the speeding drivers with a “solver” model and the police with an “auditor” model, similar to our math problem-solving example at the start. As proof of concept, we test a particular instantiation of our game-theoretic alignment framework by applying it to the hallucination reduction setting.
In this instantiation, the solver sees a LeetCode-style coding problem and is tasked with either attempting a solution or abstaining from responding. If it chooses to attempt, the auditor receives the coding prompt along with the solver’s attempted solution, and it tries to expose a bug in the code. Of course, both solver and auditor have noisy actions (e.g., a solver may be trying to solve honestly, but it hallucinates and accidentally solves incorrectly). We thus model the problem as a bandit optimization, where rewards are generally stochastic and are revealed to each LLM after each round (i.e., one response each from solver and auditor) with no other information.
This setting defines a two-player adversarial game, where the LLMs are actively competing against each other. As per standard practice, we have the solver and auditor learn through reinforcement learning. Specifically, we used Group-Relative Policy Optimization (GRPO), a standard algorithm for LLM “post-training,” which involves taking an existing pre-trained model with raw language capabilities and teach it domain-specific behaviors/skills. We saw that by co-training in this pipeline, and having the models punish each other for solving incorrectly or auditing unnecessarily, there was a 32% decrease in hallucinations relative to baselines.
To summarize, at a high level, our algorithm is as follows:
- A meta-controller (i.e. multi-armed bandit algorithm) chooses reward configuration \(\mathbf{r} \in \mathbb{R}^{d}\). In our setting, we chose Thompson sampling, a technique known for having strong empirical performance on these kinds of bandit problems.
- The solver and auditor are iteratively updated for \(n\) rounds via GRPO, through the two-player adversarial game and payoffs defined by \(\mathbf{r}\). This is an outer-iteration.
- An “alignment score” is assigned to the solver and auditor’s performance. This score is fed back to the meta-controller, updating how it chooses future reward configurations.
- Repeat!
In general, the alignment score can be anything you want it to be: as long as you can evaluate it in hindsight (given a batch of solver/auditor responses), you can have the algorithm optimize for it. So, how well does this optimization procedure actually work?
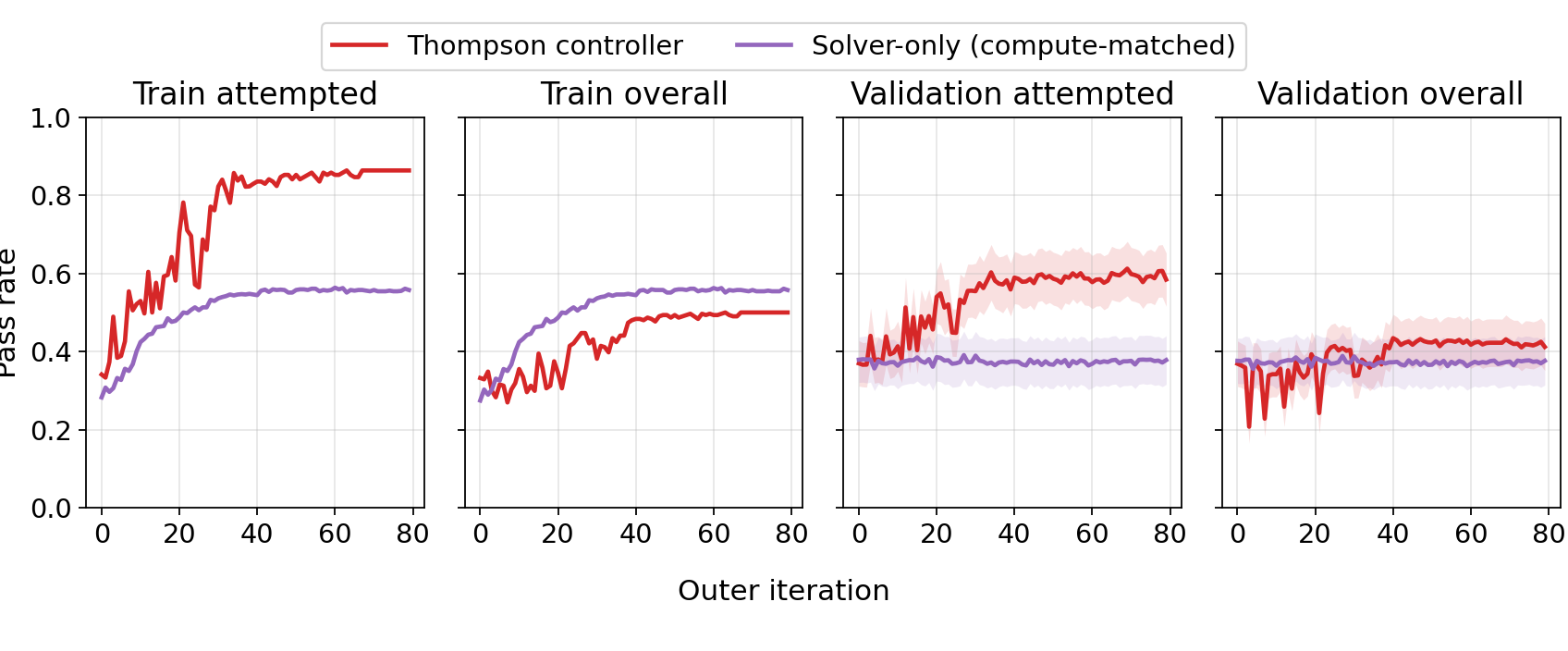
In the plots above, we see that by the end of training, whenever the the solver attempts to solve a coding problem, its pass rate increases from around 40% to 60%, relative to standard post-training (the solver-only baseline). This suggests that the solver is correctly learning to abstain on hard problems which it can’t reliably solve. On the other hand, its overall pass rate remains the same, suggesting that the solver is correctly attempting on “easy” problems which it can reliably solve.
One might wonder, though, is it possible that we just happened to design very good rewards for the Thompson controller? What if we just took a highly preferred reward configuration preferred by Thompson at the end of training, and use that to train the solver-auditor pipeline from scratch?
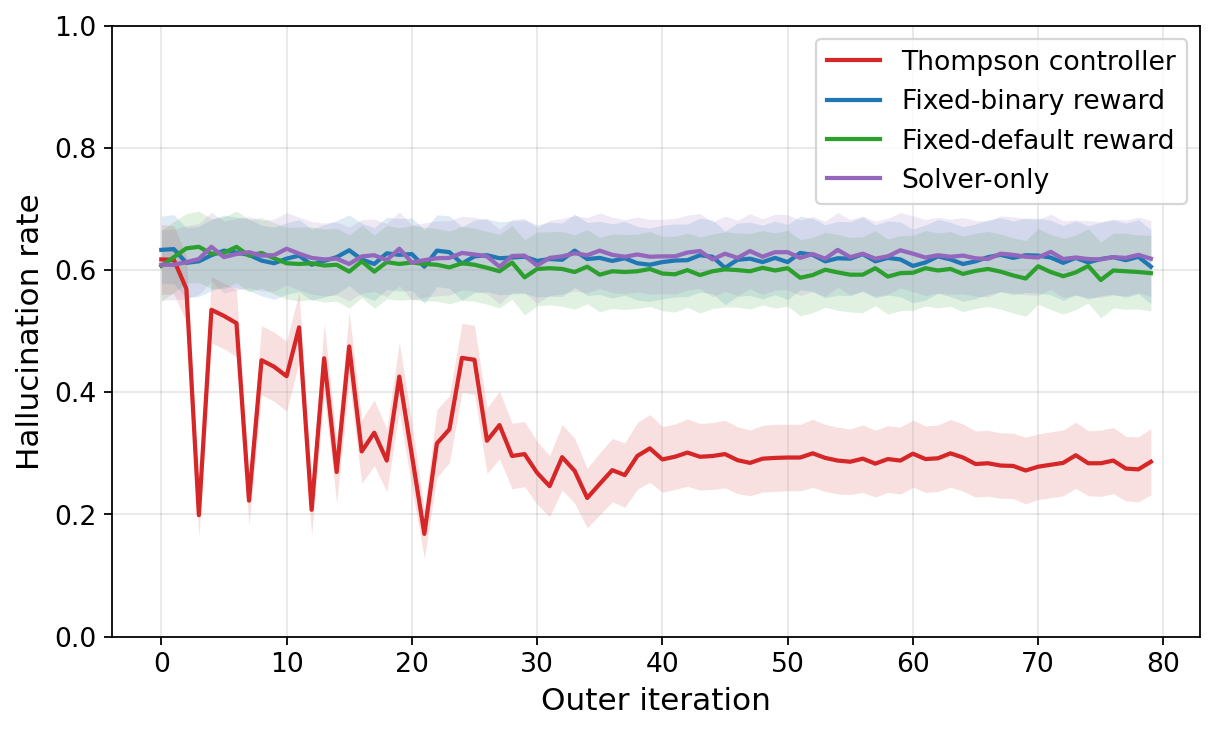
From the graph above, it turns out that even taking the highly preferred \(\mathbf{r}\) and setting it as the “fixed-default” reward profile doesn’t reduce hallucinations from the baseline. This justifies our aforementioned hypothesis that fixed rewards are inherently the issue! In fact, there are some simple but compelling mathematical arguments to suggest why this is the case; see the paper for a more detailed discussion of the game-theoretic analysis.
Applications to AI Safety
This work is most immediately relevant to the idea in AI safety of scalable oversight, where we try to monitor for unsafe behaviors in ever-growing models. Indeed, many labs have empirical shown that weak-to-strong oversight phenomenon is quite successful—a model as weak as GPT-4o can audit a model as strong as GPT-o3. However, we’ve shown that safety depends not only on the competence of the monitor but on whether monitoring remains incentivized. Indeed, if you change the model you’re monitoring, there is a chance that any safety guarantee you’ve built up can collapse. Thus, we claim that one possible way forward in safety is to build complementary monitoring systems while building new models. We also claim that AI alignment, the problem of making AI agent work together and honestly with humans, is only possible if the game-theoretic incentives are present in their training.
tags: