Minimizing Regret

Hazan Lab @ Princeton University
Reinforcement learning without rewards
by abby, Elad Hazan
The following post is based on this paper.
When humans interact with the environment, we receive a series of signals that indicate the value of our actions. We know that chocolate tastes good, sunburns feel bad, and certain actions generate praise or disapproval from others. Generally speaking, we learn from these signals and adapt our behavior in order to get more positive “rewards” and fewer negative ones.
Reinforcement learning (RL) is a sub-field of machine learning that formally models this setting of learning through interaction in a reactive environment. In RL, we have an agent and an environment. The agent observes its position (or “state”) in the environment and takes actions that transition it to a new state. The environment looks at an agent’s state and hands out rewards based on a hidden set of criteria.
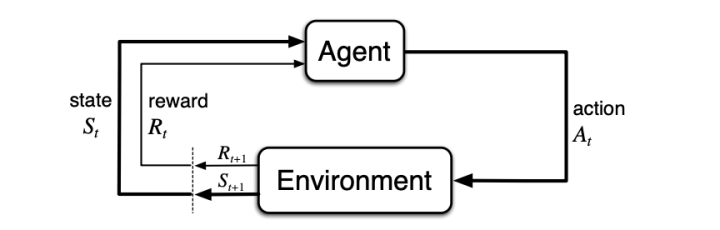
Source: Reinforcement Learning: An Introduction. Sutton & Barto, 2017.
Typically, the goal of RL is for the agent to learn behavior that maximizesthe total reward it receives from the environment. This methodology has led to some notable successes: machines have learned how to play Atari games, how to beat human masters of Go, and how to write long-form responses to an essay prompt.
But what can we learn without an external reward signal?
It seems like a paradoxical question to ask, given that RL is all about rewards. But even though the reward paradigm is fundamentally flexible in many ways, it is also brittle and limits the agent’s ability to learn about its environment. This is due to several reasons. First, a reward signal directs the agents towards a single specific goal that may not generalize. Second, the reward signal may be sparse and uninformative, as we illustrate below.
Imagine that you want a robot to learn to navigate through the following maze.
Case 1: Sparse Rewards. The agent gets a reward of +1 when it exits the maze, and a reward of 0 everywhere else. The agent doesn’t learn anything until it stumbles upon the exit.
⇒ Clear reward signals are not always available.
Case 2: Misleading Rewards. The agent gets a reward of +1 at the entrance and a reward of +10 at the exit. The agent incorrectly learns to sit at the entrance because it hasn’t explored its environment sufficiently.
⇒ Rewards can prevent discovery of the full environment.
These issues are easy to overcome in the small maze on the left. But what about the maze on the right? As the size of the environment grows, it’ll get harder and harder to find the correct solution — the intractability of the problem scales exponentially.
So what we find is that there is powerin being able to learn effectively in the absence of rewards. This intuition is supported by a body of research that shows learning fails when rewards aren’t dense or are poorly shaped; and fixing these problems can require substantial engineering effort.
By enabling agents to discover the environment without the requirement of a reward signal, we create a more flexible and generalizable form of reinforcement learning. This framework can be considered a form of “unsupervised” RL. Rather than relying on explicit and inherently limited signals (or “labels”), we can deal with a broad, unlabelled pool of data. Learning from this pool facilitates a more general extraction of knowledge from the environment.
Our new approach: Maximum Entropy
In recent work, we propose finding a policy that maximizes entropy (which we refer to as a MaxEnt policy), or another related and concave function of the distribution. This objective is reward-independent and favors exploration.
In the video below, a two-dimensional cheetah robot learns to run backwards and forwards, move its legs fast and in all different directions, and even do flips. The cheetah doesn’t have access to any external rewards; it only uses signals from the MaxEnt policy.
Entropy is a function of the distribution over states. A high entropy distribution visits all states with near-equal frequency — it’s a uniform distribution. On the other hand, a low entropy distribution is biased toward visiting some states more frequently than others. (In the maze example, a low entropy distribution would result from the agent sitting at the entrance of the maze forever.)
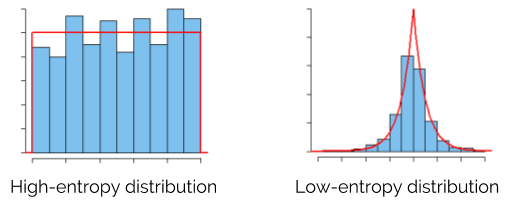
So given that policy \(\pi\) creates a distribution \(d_\pi\) over states, the problem we are hoping to solve is:
\[\pi^* = \arg \max_{\pi} \text{entropy}(d_\pi)\]When we know all the states, actions, and dynamics of a given environment, finding the policy with maximum entropy is a concave optimization problem. This type of problem can be easily and exactly solved by convex programming.
But we very rarely have all that knowledge available to use. In practice, one of several complications usually arise:
- The states are non-linearly approximated by a neural network or some other function approximator.
- The transition dynamics are unknown.
- The state space is intractably large. (As an interesting example, the game of Go has more than one googol or \(10^{100}\) possible states. That’s more than the number of atoms in the universe, according to this blog from 2016, and definitely more than can fit on a computer.)
In such cases, the problem of finding a max-entropy policy becomes non-convex and computationally hard.
So what to do? If we look at many practical RL problems (Atari, OpenAI Gym), we see that there are many known, efficient solvers that can construct an optimal (or nearly-optimal) policy when they are given a reward signal.
We thus consider an oracle model: let’s assume that we have access to one of these solvers, so that we can pass it an explicit reward vector and receive an optimal policy in return. Can we now maximize entropy in a provably efficient way? In other words, is it possible to reduce this high complexity optimization problem to that of “standard” RL?
Our approach does exactly that! It is based on the Frank-Wolfe method. This is a gradient-based optimization algorithm that is particularly suited for oracle-based optimization. Instead of moving in the direction of the steepest decline of the objective function, the Frank-Wolfe method iteratively moves in the direction of the optimal point in the direction of the gradient. This is depicted below (and deserves a separate post…). The Frank-Wolfe method is a projection-free algorithm, see this exposition about its theoretical properties.
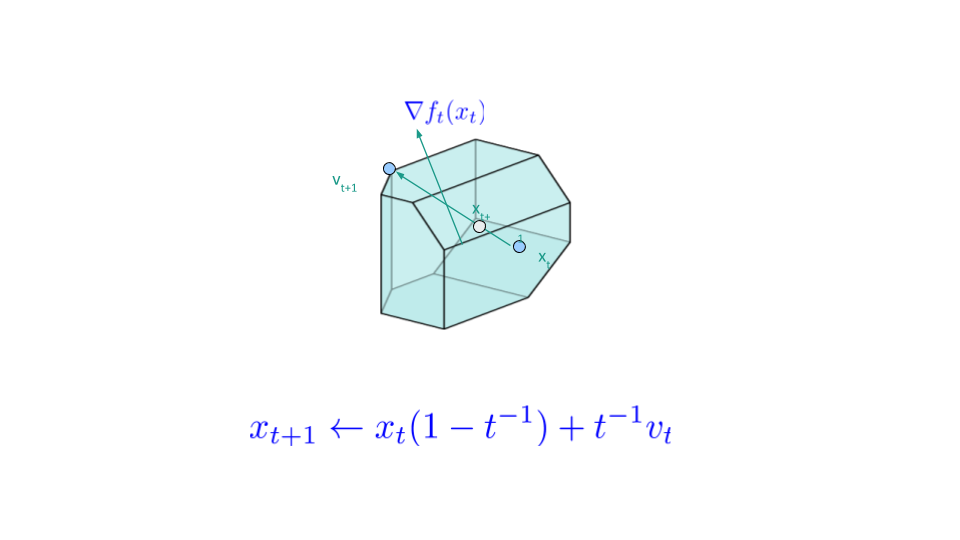
For the exact specification of the algorithm and its performance guarantee, see our paper.
Experiments
To complement the theory, we also created some experiments to test the MaxEnt algorithm on simulated robotic locomotion tasks (open source code available here). We used test environments from OpenAI Gym and Mujoco and trained MaxEnt experts for various environments.
These are some results from the Humanoid experiment, where the agent is a human-like bipedal robot. The behavior of the MaxEnt agent (blue) is baselined against a random agent (orange), who explores by sampling randomly from the environment. This random approach is often used in practice for epsilon-greedy RL exploration.
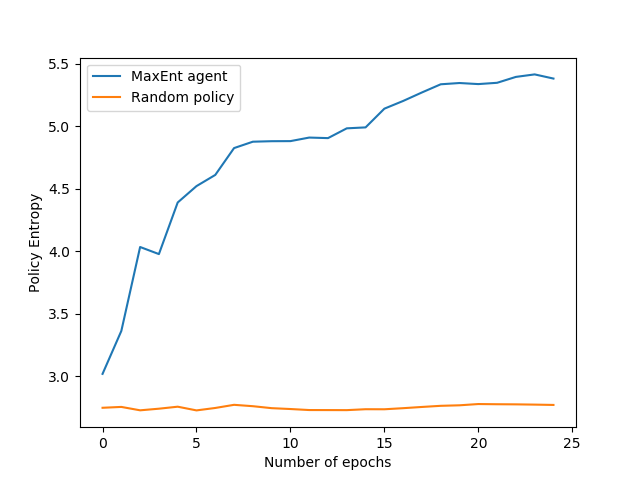
In this figure, we see that over the course of 25 epochs, the MaxEnt agent progressively increases the total entropy over the state space.
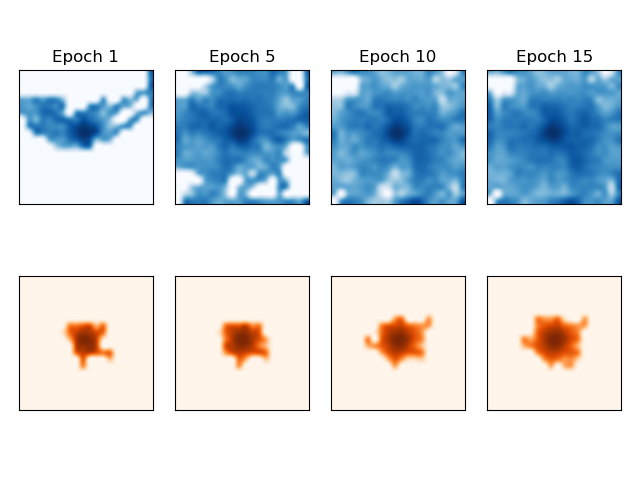
Here, we see a visualization of the Humanoid’s coverage of the $xy$-plane, where the shown plane is of size 40-by-40. After one epoch, there is minimal coverage of the area. But by the 5th, 10th, and 15th epoch, we see that the agent has learned to visit all the different states in the plane, obtaining full and nearly uniform coverage of the grid!
tags: